
Tâche de classification avec 6 algorithmes différents utilisant Python
Voici 6 algorithmes de classification pour prédire la mortalité par insuffisance cardiaque ; Random Forest, Logistic Regression, KNN, Decision Tree, SVM et Naive Bayes pour trouver le meilleur algorithme.
Introduction
Dans cet article de blog, j’utiliserai 6 algorithmes de classification différents pour prédire la mortalité par insuffisance cardiaque.
Pour ce faire, nous utiliserons des algorithmes de classification.
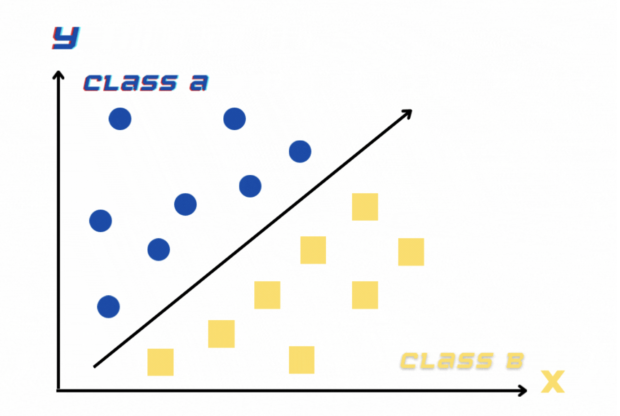
Voici les algorithmes que je vais utiliser;
- Forêt aléatoire
- Régression logistique
- KN
- Arbre de décision
- SVM
- Bayes naïf
Et après cela, je comparerai les résultats selon le;
- Précision
- Précision
- Rappeler
- Classement F1.
Ce sera plus long que mon autre article de blog, mais après avoir lu cet article, vous aurez probablement une connaissance approfondie des algorithmes de classification de l’apprentissage automatique et des métriques d’évaluation.
Si vous voulez en savoir plus sur les termes de Machine Learning, voici mon article de blog, Machine Learning AZ brièvement expliqué.
Commençons maintenant par les données.
Exploration des données
Voici l’ensemble de données du référentiel UCI Machine Learning, qui est un site Web open-source, vous pouvez accéder à de nombreux autres ensembles de donnéesqui sont spécifiquement classés en fonction de la tâche (régression, classification), des types d’attributs (catégoriel, numérique), etc.
Ou si vous voulez savoir où trouver des ressources gratuites Pour télécharger ensembles de données.
Maintenant, cet ensemble de données contient les dossiers médicaux de 299 patients qui ont eu une insuffisance cardiaque et il existe 13 caractéristiques cliniques, qui sont ;
Âge (années)Anémie : Diminution des globules rouges ou de l’hémoglobine (booléen)Hypertension artérielle : Si le patient souffre d’hypertension (booléen)Créatinine phosphokinase (CPK) : Niveau de l’enzyme CPK dans le sang (mcg/L)Diabète : Si le patient est diabétique (booléen)Fraction d’éjection : Pourcentage de sang quittant le cœur à chaque contraction (pourcentage)Plaquettes : Plaquettes dans le sang (kiloplaquettes/mL)Sexe : Femme ou homme (binaire)Créatinine sérique : Niveau de créatinine sérique dans le sang (mg/dL)Sodium sérique : taux de sodium sérique dans le sang (mEq/L)Tabagisme : si le patient fume ou non (booléen)Temps : période de suivi (jours)[ target ] Décès : Si le patient est décédé pendant la période de suivi (booléen)
Après avoir chargé les données, jetons un premier coup d’œil aux données.

Pour appliquer un algorithme d’apprentissage automatique, vous devez être sûr des types de données et vérifier si les colonnes ont des valeurs non nulles ou non.

Parfois, notre ensemble de données peut être trié avec une colonne spécifique. C’est pourquoi je vais utiliser la méthode de l’échantillon pour le savoir.
Au fait, si vous voulez voir le code source de ce projet, abonnez-vous à moi ici et j’enverrai le PDF contient des codes avec la description.
Maintenant, continuons. Voici les 5 lignes d’échantillons aléatoires de l’ensemble de données. Ne vous souvenez pas, si vous exécutez le code, les lignes seront complètement différentes car ces fonctions renvoient des lignes de manière aléatoire.

Examinons maintenant la valeur compte de l’hypertension artérielle. Je sais combien d’options existeront pour cette colonne (2) mais la vérification me fait me sentir compétent sur les données.

Oui, il semblerait que nous ayons 105 patients qui souffrent d’hypertension artérielle et 194 patients qui n’en ont pas.
Regardons les comptes de valeur de fumer.

Je pense que c’est assez avec l’exploration de données.
Faisons un peu de visualisation de données.
Bien sûr, cette partie peut être étendue en fonction des besoins de votre projet.
Voici le billet de blog, qui contient des exemples de analyse de données avec pythonen particulier en utilisant la bibliothèque pandas.
Visualisation de données
Si vous souhaitez vérifier la distribution des fonctionnalités, les éliminer ou effectuer une détection des valeurs aberrantes.

Bien sûr, ce graphique est juste informatif. Si vous voulez regarder de plus près pour détecter les valeurs aberrantes, vous devez dessiner un graphique chacun.

Passons maintenant à la partie sélection des fonctionnalités.
Soit dit en passant, Matplotlib et seaborn sont des frameworks de visualisation de données très efficaces. Si vous voulez en savoir plus à leur sujet, voici mon article, à propos de Visualisation de données pour l’apprentissage automatique avec Python.
Sélection de fonctionnalité
APC
Okey, ne sélectionnons pas nos fonctionnalités.
En faisant l’ACP, nous pouvons en fait trouver les n nombres d’entités pour expliquer le pourcentage x de la trame de données.
Ici, il semble qu’environ 8 fonctionnalités nous suffiront pour expliquer 80 % de l’ensemble de données.

Graphique de corrélation
Les caractéristiques associées ruineront les performances de notre modèle, donc après avoir fait l’ACP, dessinons une carte de corrélation pour éliminer les caractéristiques corrélées.
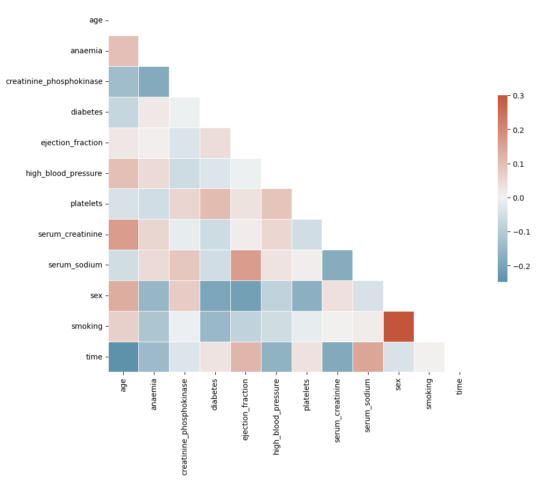
Ici, vous pouvez voir que le sexe et le tabagisme semblent fortement corrélés.
Le but principal de cet article est de comparer les résultats des algorithmes de classification, c’est pourquoi je n’éliminerai pas les deux, mais vous pouvez le faire dans votre modèle.
Modélisme
Il est maintenant temps de créer votre modèle d’apprentissage automatique. Pour ce faire, nous devons d’abord diviser les données.
Train-Test Split
L’évaluation des performances de votre modèle sur les données que le modèle ne connaît pas est la partie cruciale du modèle d’apprentissage automatique. Pour ce faire, généralement, nous divisons les données 80/20.
Une autre technique encore est utilisée pour évaluer le modèle d’apprentissage automatique, qui est la validation croisée. La validation croisée est utilisée pour sélectionner le meilleur modèle d’apprentissage automatique parmi vos options. On l’appelle parfois un ensemble de développement, pour plus d’informations, vous pouvez rechercher les vidéos d’Andrew NG, qui sont très informatives.
Passons maintenant aux métriques d’évaluation du modèle.
Métriques d’évaluation du modèle
Découvrons maintenant les métriques d’évaluation du modèle de classification.
Précision
Si vous prédisez Positif, quel est le pourcentage de choix précis ?
Rappeler
Taux de vrais positifs contre tous les positifs.
Note F1
La moyenne harmonique du rappel et la précision
Pour en savoir plus sur la classification, voici mon article : Classification AZ brièvement expliquée.
Voici la formule de précision, de rappel et de score f1.



Classificateur de forêt aléatoire
Notre premier algorithme de classification est la forêt aléatoire.
Après application de cet algorithme, voici les résultats.
Si vous voulez voir le code source, veuillez vous abonner à moi ici gratuitement.
Je vous enverrai le PDF, qui comprend le code avec une explication.

Maintenant, continuons.
Régression logistique
Voici un autre exemple de classification.
La régression logistique utilise la fonction sigmoïde pour effectuer une classification binaire.
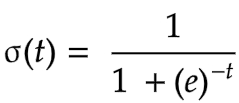

L’exactitude et la précision de celui-ci semblent plus élevées.
Continuons à chercher le meilleur modèle.
KN
Okey, appliquons maintenant le voisin le plus proche K et voyons les résultats.
Mais lors de l’application de Knn, vous devez sélectionner le “K”, qui est le numéro du voisin que vous choisirez.
Pour ce faire, utiliser une boucle semble être le meilleur moyen.

Maintenant, il semble que 2 ait la meilleure précision, tout en éliminant l’intervention humaine, découvrons le meilleur modèle en utilisant le code.

Après avoir choisi k=2, voici la précision. Il semble que K-NN ne fonctionne pas bien. Mais peut-être devons-nous éliminer les caractéristiques corrélées de la normalisation, bien sûr, ces opérations peuvent être variées.

Fantastique, continuons.
Arbre de décision
Il est maintenant temps d’appliquer l’arbre de décision. Pourtant, nous devons trouver le meilleur score de profondeur pour le faire.
Ainsi, lors de l’application de notre modèle, il est important de tester différentes profondeurs.

Et pour trouver la meilleure profondeur parmi les résultats, continuons à automatiser.

Bon, maintenant nous trouvons la profondeur la plus performante. Découvrons la précision.

Excellent, continuons.
Soutenir la machine vectorielle
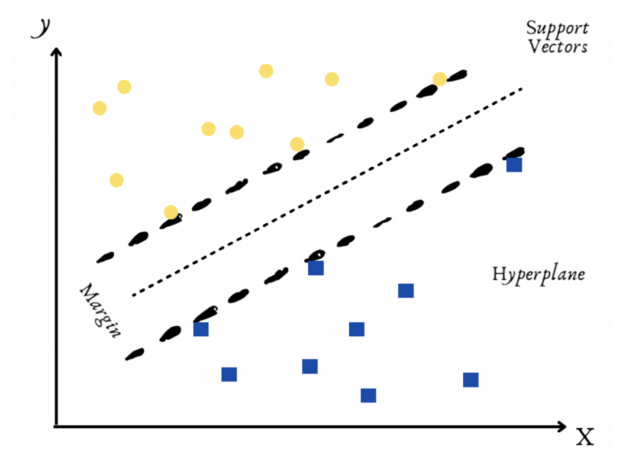
Maintenant, pour appliquer l’algorithme SVM, nous devons sélectionner le type de noyau. Ce type de noyau affectera notre résultat, nous allons donc itérer pour trouver le type de noyau, qui renvoie le meilleur modèle noté f1.

Okey, nous allons utiliser le noyau linéaire.
Trouvons l’exactitude, la précision, le rappel et f1_score avec un noyau linéaire.

Bayes naïf
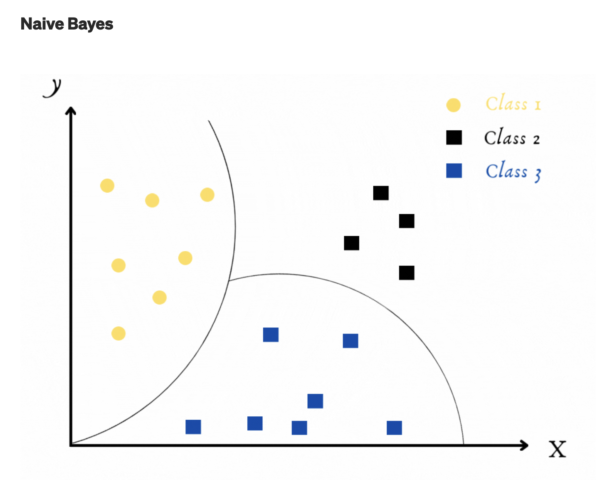
Maintenant, Naive Bayes sera notre modèle final.
Savez-vous pourquoi naïf Bayes est appelé naïf ?
Parce que l’algorithme suppose que chaque variable d’entrée est indépendante. Bien sûr, cette hypothèse est impossible lorsque l’on utilise des données réelles. Cela rend notre algorithme “naïf”.
Bon, continuons.

Dictionnaire de prédiction
Maintenant, après avoir terminé la recherche de modèle. Enregistrons des sorties entières dans une seule trame de données, ce qui nous donnera une chance d’évaluation ensemble.
Après cela, découvrons maintenant le modèle le plus précis.
Modèle le plus précis

Modèle avec la plus haute précision

Modèle avec le rappel le plus élevé

Modèle avec le score F1 le plus élevé

Conclusion
Désormais, la métrique prévue peut différer en fonction des besoins de votre projet. Vous découvrirez peut-être le modèle le plus précis ou le modèle avec le rappel le plus élevé.
C’est ainsi que vous pourrez trouver le meilleur modèle, qui répondra aux besoins de votre projet.
Si vous voulez que j’envoie le code source PDF avec une explication GRATUITEMENT, veuillez vous abonner à moi ici.
Merci d’avoir lu mon article !
J’ai tendance à envoyer 1 ou 2 e-mails par semaine, si vous voulez aussi un Numpy CheetSheet gratuit, voici le lien pour tu!
Si vous n’êtes toujours pas membre de Medium et que vous êtes désireux d’apprendre en lisant, voici ma référence lien.
“L’apprentissage automatique est la dernière invention que l’humanité aura jamais besoin de faire.” Nick Boström







