
Apache HBase : co-localisation de RegionServers | Adalta

Les RegionServers sont les processus qui gèrent le stockage et la récupération des données dans Apache HBasela base de données orientée colonnes non relationnelle dans Apache Hadoop. C’est à travers leurs démons que toute requête CRUD (pour Create, Read, Update et Delete) est effectuée. Avec le Master, ils sont les garants de la sauvegarde des données et de l’optimisation des performances. Dans les environnements de production, un seul RegionServer est déployé sur chaque nœud de calcul, ce qui permet de faire évoluer à la fois les charges de travail et le partage du stockage en ajoutant des nœuds supplémentaires.
Aujourd’hui, de nombreuses entreprises choisissent encore d’exécuter leur infrastructure sur site, c’est-à-dire dans leurs propres centres de données, plutôt que dans le cloud. Leurs déploiements de serveurs bare metal tirent parti de l’espace mémoire complet de chaque machine. Parmi eux, ceux dont les charges de travail reposent majoritairement sur Apache HBase n’utilisent pas toujours toutes leurs ressources. En effet, la quantité de RAM qu’un RegionServer peut consommer est limitée par la JVM Java. Si chaque RegionServer pouvait profiter de toute la RAM dont il dispose, ses performances seraient potentiellement grandement améliorées. Dans ce cas, la suppression de nœuds du cluster pourrait être envisagée, réduisant ainsi les coûts de licence qui en dépendent directement, et permettant de mieux utiliser les ressources disponibles. Dès lors, sur une infrastructure on-premise, peut-on permettre à chaque RegionServer d’exploiter plus de ressources mémoire, afin de supporter la charge de travail due à la suppression d’un ou plusieurs Workers ?
Colocation de RegionServers
Sur Apache Ambari, la taille de l’espace mémoire alloué à la JVM de chaque RegionServer peut être choisie : de 3 à 64 Go. Cependant, le Documentation conseille de ne pas dépasser 30 Go. En effet, au-delà de ce seuil, le Garbage Collector, dont la mission est de nettoyer les données qui ne sont plus utilisées en RAM, est surchargé : cela se traduit par des pauses au milieu d’une charge de travail, la rendant indisponible pendant plusieurs secondes. Une solution possible serait de multiplier le nombre de RegionServers par machine, afin de conserver des JVM de 30 Go, tout en profitant de la RAM disponible.
UN projet sur Github décrit la marche à suivre pour lancer plusieurs RegionServers sur un même host, sur une distribution HDP gérée par Ambari. C’est un script principalement composé d’un for boucle qui exécute les étapes de démarrage classiques de RegionServer, autant de fois que vous le souhaitez. Pour chaque nouvelle instance, le fichier de configuration initial sera copié et les numéros de port seront incrémentés. Les dossiers log et PID de chaque RegionServer seront créés automatiquement.
Ce script doit être placé dans le répertoire de configuration HBase, sur chacun des Workers sur lesquels on veut multiplier les RegionServers, puis être lancé par Ambari. Voici les quelques étapes manuelles nécessaires pour configurer ce script.
#!/bin/bash
mv /usr/hdp/current/hbase-regionserver/bin/hbase-daemon.sh /usr/hdp/current/hbase-regionserver/bin/hbase-daemon-per-instance.sh
cp ./hbase-daemon.sh /usr/hdp/current/hbase-regionserver/bin/hbase-daemon.sh
chmod +rwx /usr/hdp/current/hbase-regionserver/bin/hbase-daemon.sh
Bien que ces nouvelles instances ne soient pas visibles dans Ambari, elles sont néanmoins visibles sur l’interface utilisateur HBase Master. Après avoir effectué chacune de ces étapes, il vous suffit de démarrer chaque RegionServer via l’interface Ambari. En effet, lorsqu’une action sera effectuée sur un RegionServer via l’interface Ambari, elle sera également lancée sur chaque RegionServer du même host. Par exemple, si un restart des RegionServers de l’hébergeur travailleur01 se fait via Ambari, toutes les nouvelles instances RegionServer de l’hôte travailleur01 lancera également une restart.

Environnement et méthodologie de test
Pour mesurer l’impact sur les performances de ces nouvelles instances RegionServers, l’utilisation d’un YCSB suite de tests est pertinente. YCSB (pour Yahoo! Référence de service cloud) est une suite de programmes open source utilisés pour évaluer les capacités de récupération et de maintenance des programmes informatiques. Il est souvent utilisé pour comparer les performances relatives des systèmes de gestion de base de données NoSQL, tels que HBase. Cette suite de tests reproduit les étapes suivantes dans chaque itération :
- Création (ou re-création) d’une table de 50 régions
- Insertions avec de nouvelles entrées (~150 Go)
- Charge de travail YCSB A, “Mise à jour lourde” : cette charge de travail est composée de 50/50 de lectures et d’écritures. Les mises à jour sont effectuées sans lire l’élément au préalable. Un exemple d’application serait les cookies d’une session sur un site web.
- Charge de travail YCSB F, « Lire-modifier-écrire » : pour cette charge de travail, chaque élément sera lu, modifié puis réécrit. Un exemple d’application serait une base de données où les enregistrements d’un utilisateur sont lus et modifiés par l’utilisateur.
Pour chaque charge de travail, le temps d’exécution (en secondes) et le taux d’opération (en opérations/seconde) seront récupérés. Ces tests ont été réalisés sur un cluster HDP 2.6.5, sur 4 Workers bare-metal avec 180 Go de RAM et 4 disques de 3 To chacun, avec une bande passante inter-machine de 10 Go/s. Tous les RegionServers de ces 4 Workers formaient un « Region Server Group », et étaient donc exclusivement utilisés pour le jeu de test, et pour aucune autre charge de travail. Dans chaque situation, l’ensemble de test a été lancé au moins trois fois.
Ajout de nouvelles instances
Cette première étape consiste à supprimer un nœud du cluster, puis à ajouter des RegionServers sur différents hôtes pour mesurer les performances. Le tableau suivant montre les résultats : ‘w1’ signifie ‘Worker 1’ et les sticks représentent le nombre de RegionServers sur chaque hôte. Enfin l’indication « w̶1̶ » indique que le nœud « Worker 1 » a été supprimé du cluster HBase pour le test donné. Les résultats présentés sont des moyennes calculées sur toutes les batteries de test.
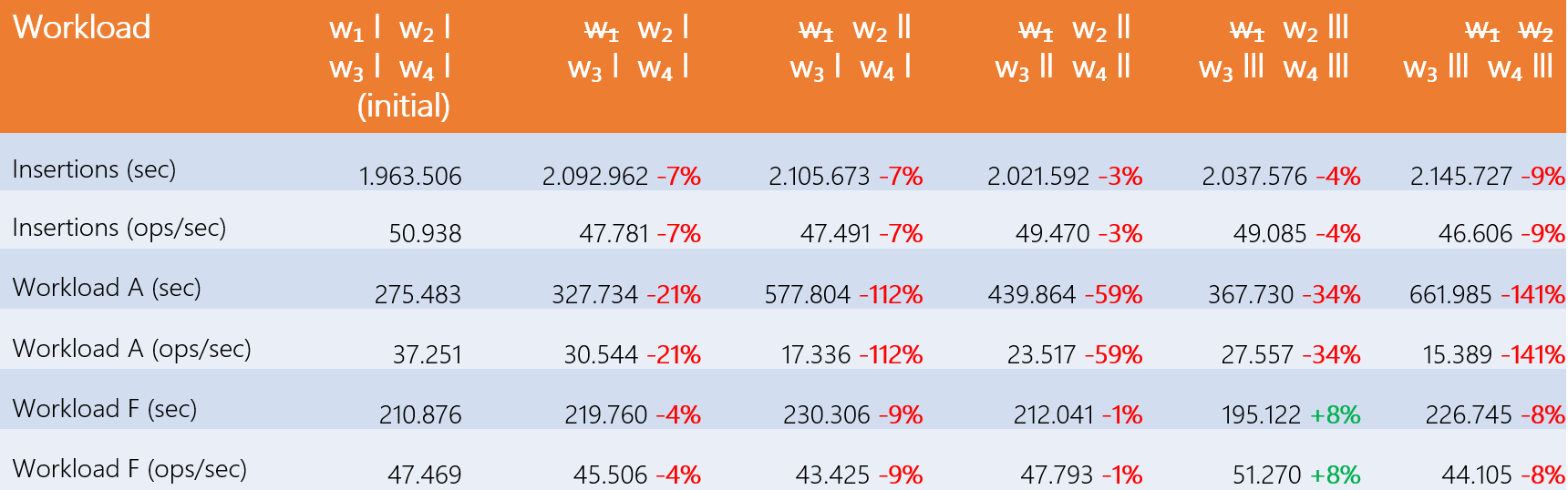
On remarque que l’ajout d’un ou plusieurs RegionServers sur chaque host ne compense pas la perte d’une machine. De plus, un déséquilibre des RegionServers d’un hôte à l’autre fait chuter les performances. En effet, le maître voit chaque RegionServer indépendamment, comme s’ils avaient chacun leur propre machine. Ainsi, les régions (tracés de données) sont réparties uniformément sur chaque RegionServers. Un hébergeur avec plus de RegionServers qu’un autre devra traiter plus de régions : la charge de travail est alors moins bien répartie entre les machines. Comme un RegionServer ne compense pas la perte d’une machine, cela prouve l’existence d’un goulot d’étranglement à une certaine étape du flux de données.
Optimisation des configurations
Cette étude consiste à modifier des propriétés sur Ambari afin d’obtenir de meilleures performances de nos nouveaux RegionServers. Les biens en question sont les suivants :
- Noeuds de données :
- Nombre maximum de threads (
dfs.datanode.max.transfer.threads) - RAM allouée aux DataNodes (
dtnode_heapsize)
- Nombre maximum de threads (
- Serveurs de région :
- Nombre de gestionnaires (
hbase.regionserver.handler.count) - RAM allouée aux RegionServers (
hbase_regionserver_heapsize)
- Nombre de gestionnaires (
Le tableau suivant montre les performances obtenues initialement, puis avec 2 RegionServers par Worker, puis avec la configuration la plus efficace.
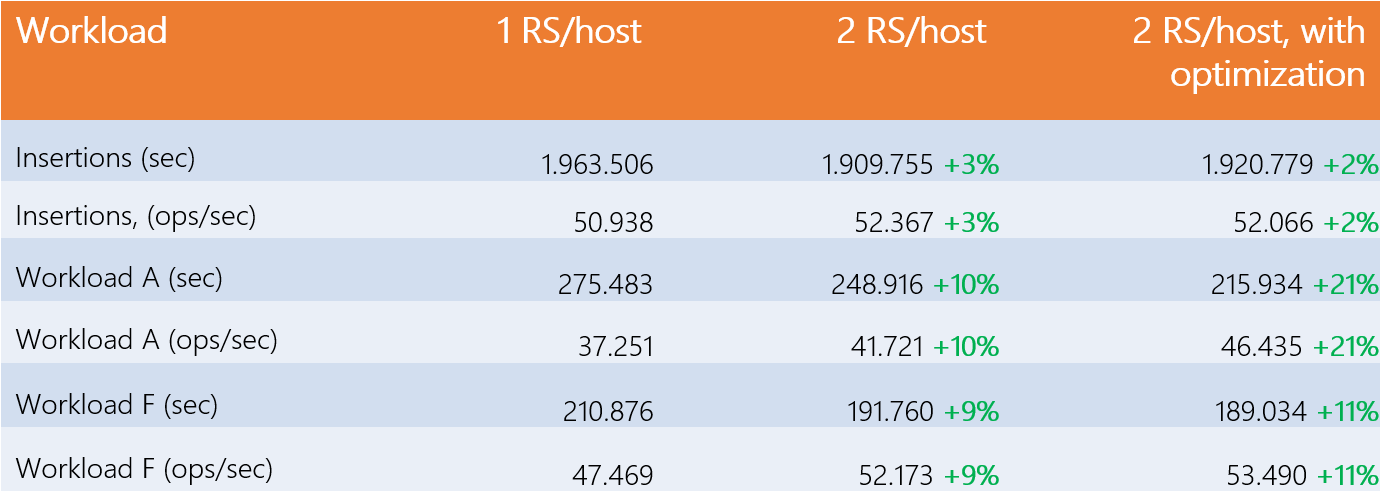
Comme on peut le voir, les gains de l’ajout d’un RegionServer sur chaque Worker sont de 10% : ils sont donc négligeables, et expliquent les résultats de la première étude, amplifiés par la prise en compte d’une marge d’erreur réaliste de 3%. Les gains avec 3 RegionServers ou plus par Worker sont identiques au cas précédent, donc aucun bénéfice n’est généré.
Parmi les propriétés testées, seules deux d’entre elles ont abouti à la configuration la plus efficace pour augmenter les gains avec 2 RegionServers par Worker. Ajout de 10 Go de RAM aux RegionServers (hbase_regionserver_heapsize=30.720) et 4000 threads pour le transfert de données DataNode (dfs.datanode.max.transfer.threads=20.480), nous obtenons 11 % de gain pour la charge de travail A et 21 % pour F, qui sont les deux charges de travail incluant les lectures. Encore une fois, les gains avec 3 RegionServers après optimisations n’impliquent aucun changement. Bien qu’un gain de 21 % ne puisse pas être qualifié de significatif, il n’en demeure pas moins intéressant.
Enfin, de nouvelles propriétés ont été testées mais n’ont pas pu apporter de bénéfice concret :
- io.file.buffer.size: taille du tampon d’E/S via le DataNode.
- dfs.datanode.handler.count: nombre de handlers disponibles par DataNode pour répondre aux requêtes.
- dfs.datanode.balance.bandwidthPerSec: niveau maximum de bande passante que chaque DataNode peut utiliser.
- dfs.datanode.readahead.bytes: nombre d’octets à lire avant la lecture de l’élément.
- dfs.client.read.shortcircuit.streams.cache.size: taille du cache du client lors d’une lecture en court-circuit.
Analyse des métriques
L’analyse de différentes métriques d’activité nous a permis d’identifier des hypothèses expliquant les gains obtenus. Les métriques en question, récupérées sur chaque machine, sont : l’évolution de la charge CPU (utilisateur, système), celle de la RAM (utilisé, libre, échanger), celui des E/S (nombre de transferts, taux de lecture/écriture, taux de requête) et la répartition des charges (exécuter la file d’attente, charge moyennenombre de tâches en attente du disque).
Hypothèses:
- L’augmentation du nombre de threads Datanode augmente les demandes de lecture/écriture sur les disques, générant des tâches en attente d’E/S disponibles. Le nombre de threads par défaut était donc insuffisant lors de l’ajout d’un RegionServer pour atteindre le seuil de performance des DataNodes.
- Avec l’ajout de RAM sur les RegionServers, nous pouvons supposer que les lectures sont effectuées sur le BlockCache, réduisant ainsi le nombre de requêtes de lecture allant sur le disque, ce qui réduit les tâches en attente de disque. Cela expliquerait les avantages des charges de travail en lecture, négligeables pour les charges de travail en écriture, avec ou sans optimisation.
Dès lors, on peut dire que le goulot d’étranglement se situe sûrement sur les disques. En effet, les performances d’insertion augmentent légèrement grâce à la pression qu’exerce un second RegionServer sur les disques, mais cela ne va pas plus loin justement car cela ne dépend que des disques. Aussi, les performances en lecture sont meilleures grâce à la pression des threads, mais surtout grâce à l’élargissement des différents caches de lecture. De plus, il est intéressant de noter que le nombre de requêtes ne double pas complètement lors de l’ajout d’un second RegionServer. Sans goulot d’étranglement, les performances n’auraient pas doublé.
Ajout de disques
Jusqu’à présent, les machines fonctionnaient avec quatre disques de 3 To, mais comment les performances changeraient-elles si elles en avaient plus ? 8 disques ont donc été ajoutés à chaque machine. Les résultats des tests sont présentés dans le tableau suivant :
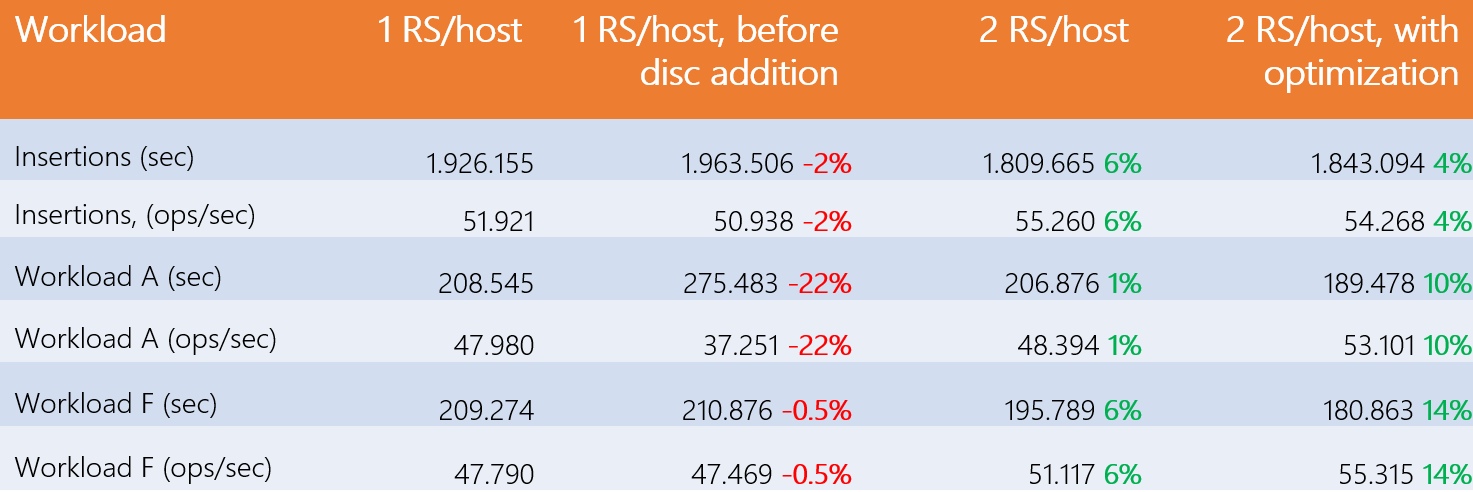
Tout d’abord, on remarque une différence de performances de 22% sur la charge A par rapport au cas initial, alors qu’elles sont plus ou moins identiques pour les deux autres types de tests. En revanche, sur la même charge de travail, les gains passent à 1% avec 2 RegionServers par host, puis 10% avec l’optimisation. L’augmentation du nombre de disques a donc eu un impact significatif sur les performances de notre RegionServer, mais l’ajout d’une instance supplémentaire, même avec optimisation, n’a que peu d’intérêt.
Conclusion
Comme nous l’avons vu, dans notre environnement, les performances en écriture et en lecture sont loin d’être doublées en ajoutant un second RegionServer sur chaque Worker. Le DataNode agit alors comme un goulot d’étranglement logiciel et apporte au mieux un gain de 21%. Les RegionServers sont optimisés pour tirer le maximum de performances par eux-mêmes et fonctionnent en trio avec les Yarn Node Managers et les HDFS DataNodes. Cet environnement a été conçu pour n’avoir qu’un seul RegionServer par Worker, comme le montre le gain de performances avec un seul RegionServer lors de l’ajout de disques.
En revanche, ce cas peut profiter à un cluster avec un surplus de régions. En effet, les régions sont équitablement réparties entre chaque RegionServer, sans entraîner de perte de performances. Aussi, pour certains cas d’utilisation tels que la charge de travail F, la suppression d’un nœud physique peut être envisagée afin d’économiser les coûts de licence et d’exploitation sans entraîner une baisse significative des performances.







