
Partitionnement pour les performances dans un système de base de données de partitionnement
Dans un post précédent, j’ai décrit un système de partitionnement pour adapter le débit et les performances des expenses de travail de requête et d’ingestion. Dans cet write-up, je présenterai une autre procedure courante, le partitionnement, qui offre d’autres avantages en termes de performances et de gestion pour une base de données de partitionnement. Je décrirai également remark gérer efficacement les partitions pour les prices de travail de requête et d’ingestion, et comment gérer les partitions froides (anciennes) où les exigences de lecture sont assez différentes des partitions chaudes (récentes).
Sharding vs partitionnement
Le partitionnement est un moyen de fractionner les données dans un système de foundation de données distribué. Les données de chaque partition n’ont pas à partager des ressources telles que le processeur ou la mémoire, et peuvent être lues ou écrites en parallèle.
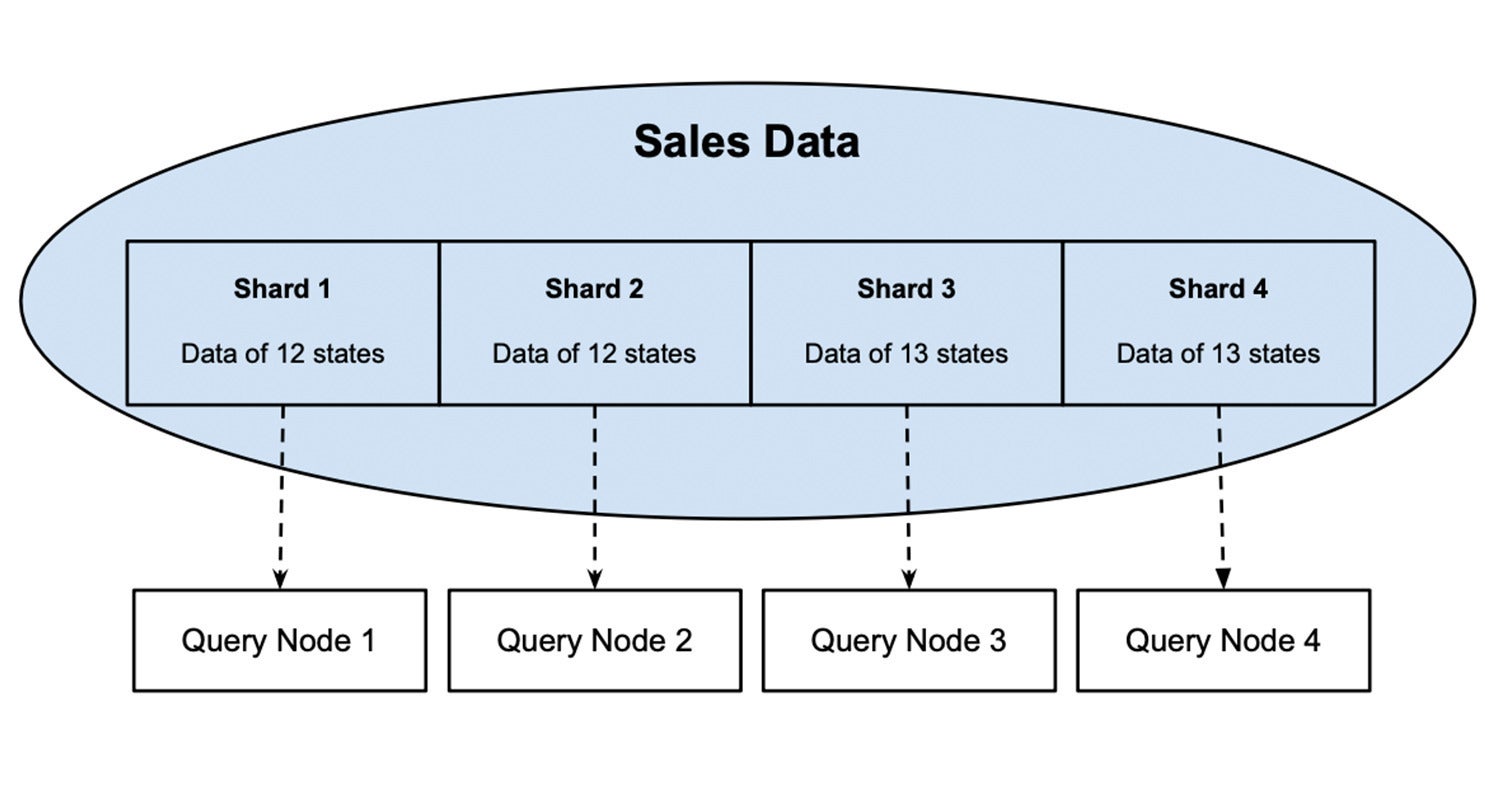
La determine 1 est un exemple de foundation de données de partitionnement. Les données sur les ventes de 50 États d’un pays sont divisées en quatre partitions, chacune contenant les données de 12 ou 13 États. En attribuant un nœud de requête à chaque partition, une tâche qui lit les 50 états peut être répartie entre ces quatre nœuds exécutés en parallèle et sera exécutée quatre fois as well as rapidement par rapport à la configuration qui lit les 50 états par un nœud. Vous trouverez additionally d’informations sur les fragments et leurs effets de mise à l’échelle sur les expenses de travail d’ingestion et de requête dans mon report précédent.
 InfluxData
InfluxDataDetermine 1 : Les données de ventes sont divisées en quatre partitions, chacune affectée à un nœud de requête.
Le partitionnement est un moyen de diviser les données de chaque partition en partitions sans chevauchement pour une gestion parallèle ultérieure. Cela réduit la lecture de données inutiles et permet de mettre en œuvre efficacement des politiques de conservation des données.
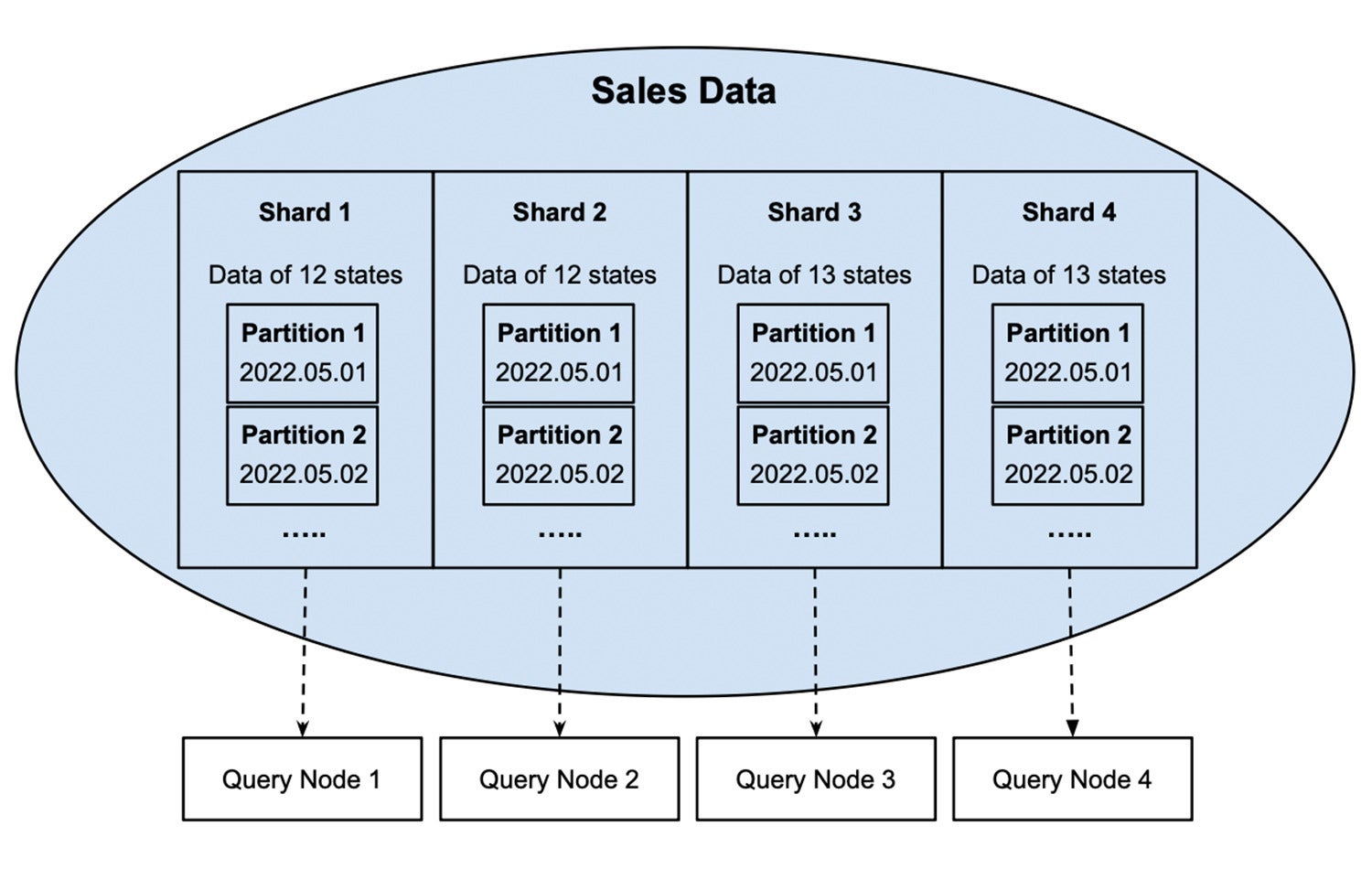
Dans la determine 2, les données de chaque partition sont partitionnées par jour de vente. Si nous devons créer un rapport sur les ventes d’un jour spécifique, comme le 1er mai 2022, les nœuds de requête n’ont besoin que de lire les données de leurs partitions correspondantes du 2022.05.01.
 InfluxData
InfluxDataFigure 2 : Les données de vente de chaque partition sont ensuite divisées en partitions de jour sans chevauchement.
Le reste de cet report se concentrera sur les effets du partitionnement. Nous verrons remark gérer efficacement les partitions pour les rates de travail de requête et d’ingestion sur les données chaudes et froides.
Effets de partitionnement
Les trois avantages les furthermore courants du partitionnement des données sont l’élagage des données, le parallélisme intra-nœud et la suppression rapide.
Élagage des données
Un système de base de données peut contenir plusieurs années de données, mais la plupart des requêtes ne doivent lire que des données récentes (par exemple, “Combien de commandes ont été passées au cours des trois derniers jours ?”). Le partitionnement des données en partitions sans chevauchement, comme illustré à la figure 2, permet d’ignorer facilement des partitions hors limites entières et de lire et de traiter uniquement des ensembles de données pertinents et très petits pour renvoyer rapidement des résultats.
Parallélisme intra-nœud
Le traitement multithread et les données de streaming sont essentiels dans un système de base de données pour utiliser pleinement le processeur et la mémoire disponibles et obtenir les meilleures performances possibles. Le partitionnement des données en petites partitions facilite la mise en œuvre d’un moteur multithread qui exécute un thread par partition. Pour chaque partition, davantage de threads peuvent être générés pour gérer les données au sein de cette partition. Connaître les statistiques de partition telles que la taille et le nombre de lignes aidera à allouer la quantité optimale de CPU et de mémoire pour des partitions spécifiques.
Suppression rapide des données
De nombreuses organisations ne conservent que les données récentes (par exemple, les données des trois derniers mois) et souhaitent supprimer les anciennes données dès que possible. En partitionnant les données sur des fenêtres temporelles sans chevauchement, la suppression d’anciennes partitions devient aussi easy que la suppression de fichiers, sans qu’il soit nécessaire de réorganiser les données et d’interrompre d’autres activités de requête ou d’ingestion. Si toutes les données doivent être conservées, une portion furthermore loin dans cet post décrira comment gérer différemment les données récentes et anciennes pour garantir que les systèmes offrent d’excellentes performances dans tous les cas.
Stockage et gestion des partitions
Optimisation pour les fees de travail de requête
Une partition contient déjà un petit ensemble de données, nous ne voulons donc pas stocker une partition dans de nombreux fichiers plus petits (ou des morceaux dans le cas d’une foundation de données en mémoire). Une partition doit être composée d’un seul ou de quelques fichiers.
La réduction du nombre de fichiers dans une partition présente deux avantages importants. Il réduit à la fois les opérations d’E/S lors de la lecture des données pour l’exécution d’une requête et améliore l’encodage/la compression des données. L’amélioration de l’encodage réduit à son tour les coûts de stockage et, plus vital encore, améliore la vitesse d’exécution des requêtes en lisant moins de données.
Optimisation pour les fees de travail d’ingestion
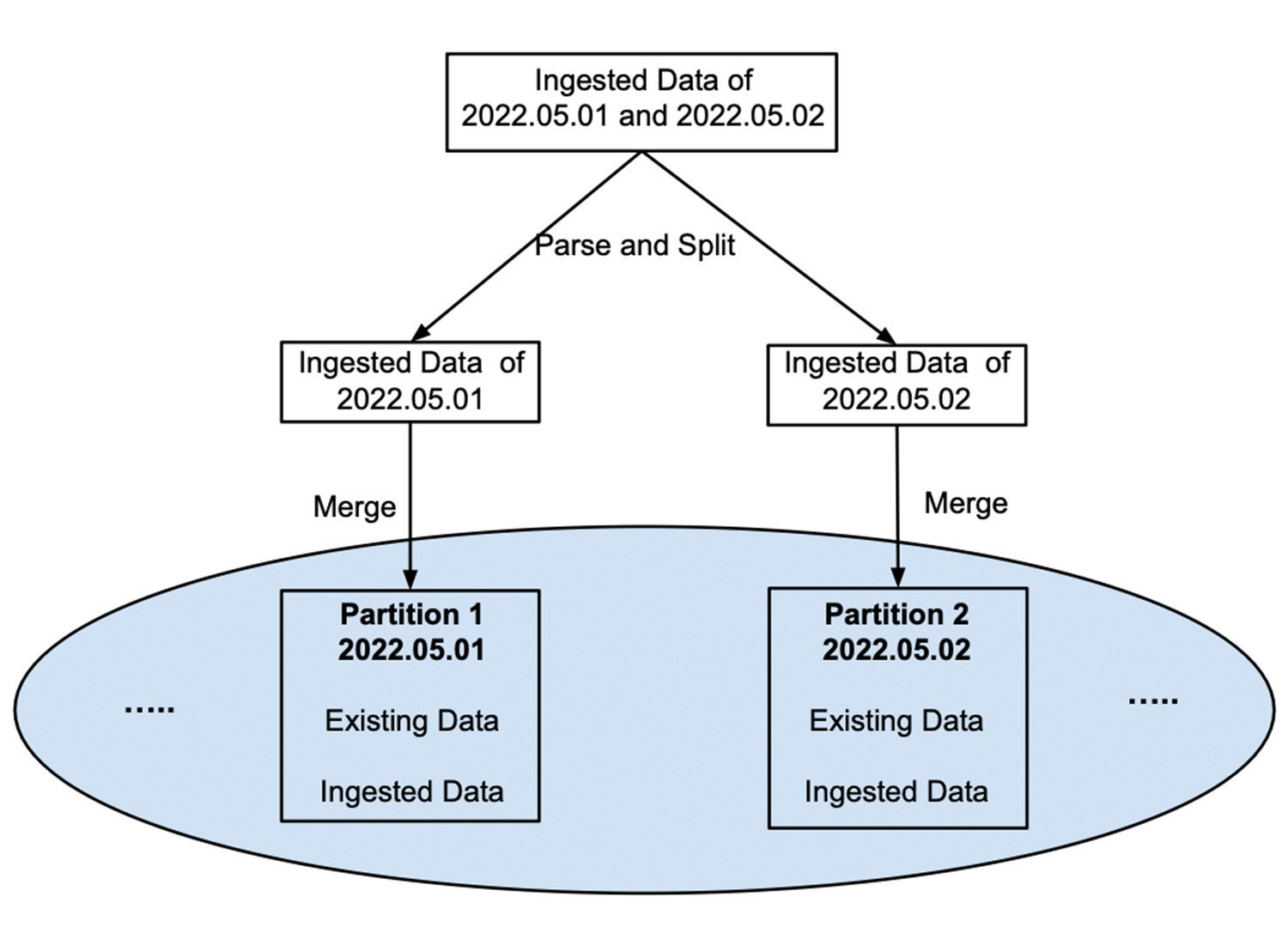
Ingestion naïve. Pour conserver les données d’une partition dans un fichier pour les avantages d’optimisation de lecture notés ci-dessus, chaque fois qu’un ensemble de données est ingéré, il doit être analysé et divisé dans les bonnes partitions, puis fusionné dans le fichier existant de sa partition correspondante, comme illustré à la figure 3.
Le processus de fusion de nouvelles données avec des données existantes prend souvent du temps en raison des E/S coûteuses et du coût de mélange et d’encodage des données de la partition. Cela entraînera une longue latence pour les réponses au shopper indiquant que les données ont été ingérées avec succès, et pour les requêtes des données nouvellement ingérées, car elles ne seront pas immédiatement disponibles dans le stockage.
 InfluxData
InfluxDataFigure 3 : Ingestion naïve dans laquelle les nouvelles données sont immédiatement fusionnées dans le même fichier que les données existantes.
Ingestion à faible latence. Pour réduire la latence de chaque ingestion, nous pouvons diviser le processus en deux étapes : l’ingestion et le compactage.
Ingestion
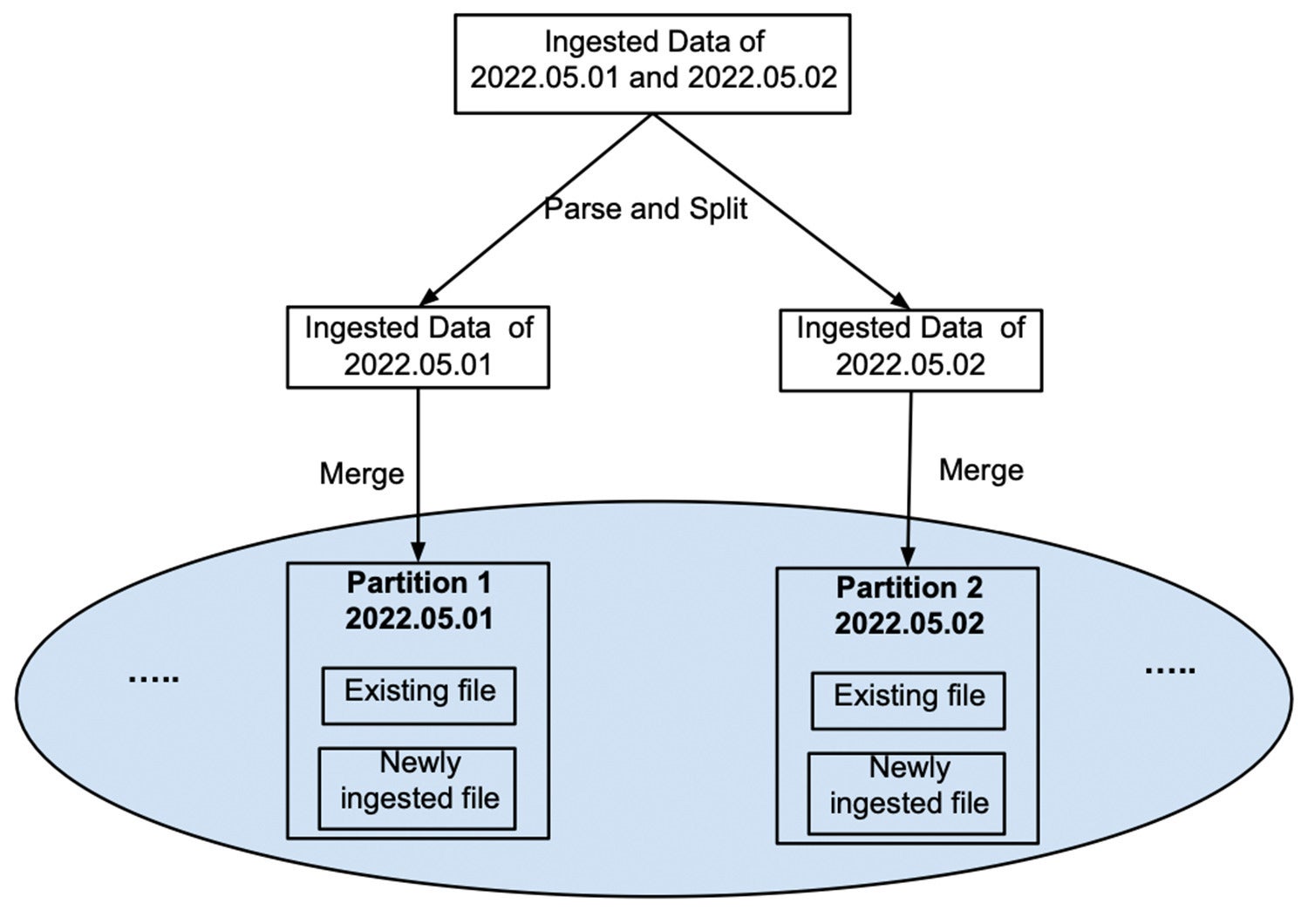
Au cours de l’étape d’ingestion, les données ingérées sont fractionnées et écrites dans leur propre fichier, comme illustré à la determine 4. Elles ne sont pas fusionnées avec les données existantes de la partition. Dès que les données ingérées sont durables avec succès, le shopper ingéré recevra un signal de réussite et le fichier nouvellement ingéré sera disponible pour interrogation.
Si le taux d’ingestion est élevé, de nombreux petits fichiers s’accumuleront dans la partition, comme illustré à la determine 5. À ce stade, une requête nécessitant des données d’une partition doit lire tous les fichiers de cette partition. Ce n’est bien sûr pas idéal pour les performances des requêtes. L’étape de compactage, décrite ci-dessous, réduit au minimum amount cette accumulation de fichiers.
 InfluxData
InfluxDataFigure 4 : Les données nouvellement ingérées sont écrites dans un nouveau fichier.
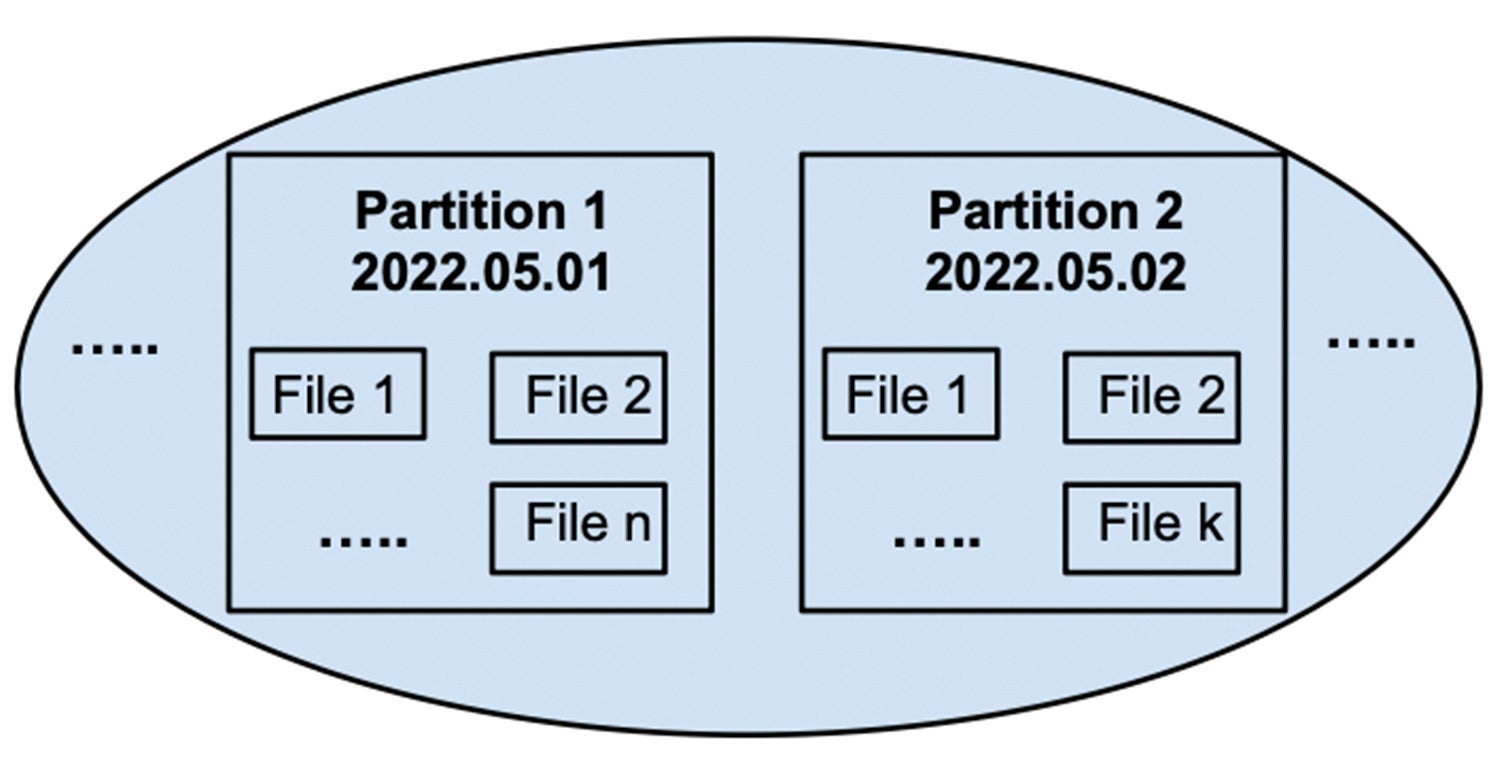 InfluxData
InfluxDataFigure 5 : Sous une demand de travail d’ingestion élevée, une partition accumulera de nombreux fichiers.
Compactage
Le compactage est le processus de fusion des fichiers d’une partition en un ou plusieurs fichiers pour de meilleures performances de requête et de compression. Par exemple, la determine 6 montre tous les fichiers de la partition 2022.05.01 fusionnés en un seul fichier, et tous les fichiers de la partition 2022.05.02 fusionnés en deux fichiers, chacun inférieur à 100 Mo.
Les décisions concernant la fréquence de compactage et la taille maximale des fichiers compactés seront différentes pour différents systèmes, mais l’objectif commun est de maintenir les performances des requêtes à un niveau élevé en réduisant les E/S (c’est-à-dire le nombre de fichiers) et en ayant des fichiers volumineux assez pour compresser efficacement.
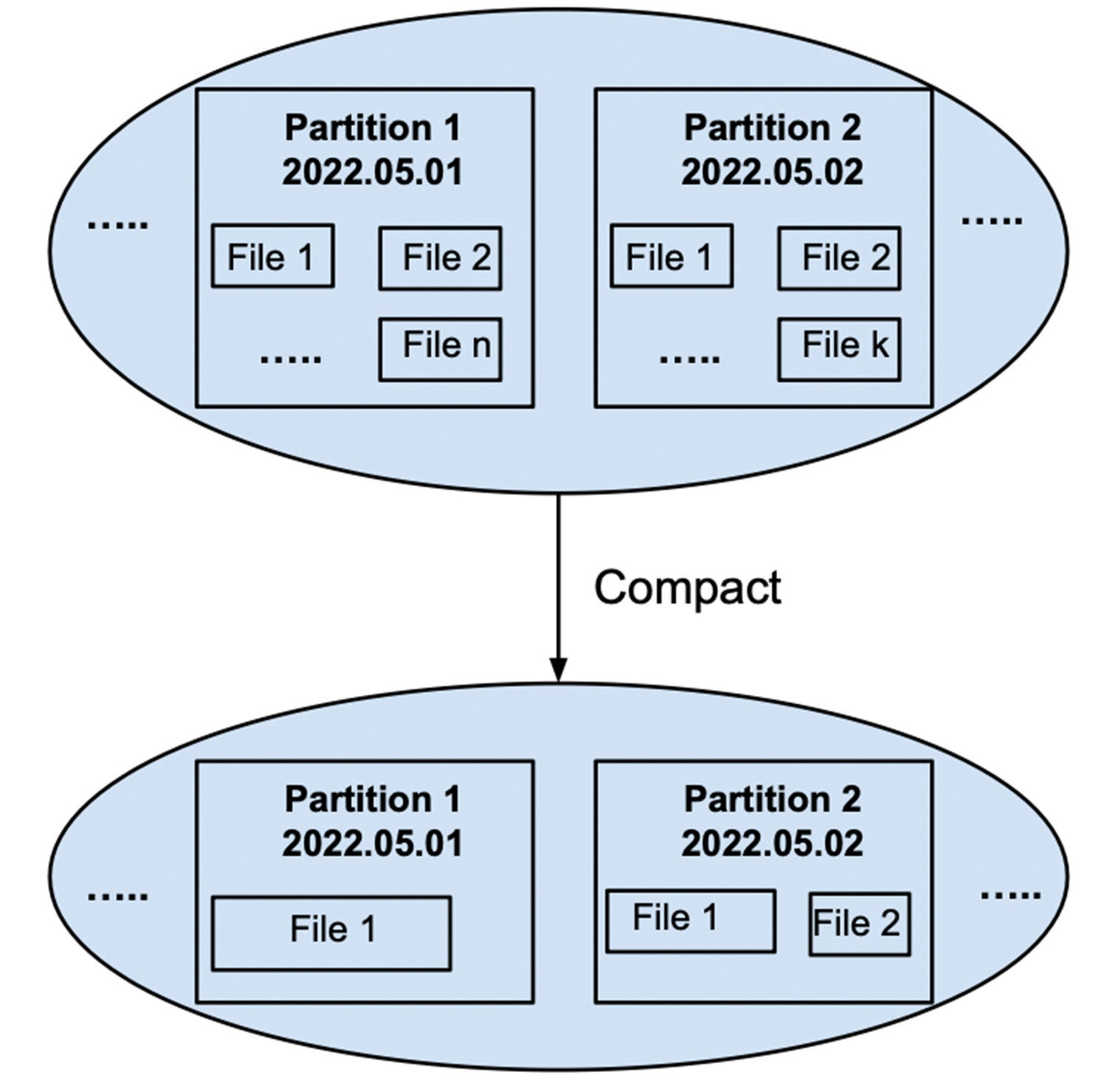 InfluxData
InfluxDataDetermine 6 : Compactage de plusieurs fichiers d’une partition en un ou plusieurs fichiers.
Partitions chaudes ou froides
Les partitions fréquemment interrogées sont considérées comme des partitions chaudes, tandis que celles qui sont rarement lues sont appelées des partitions froides. Dans les bases de données, les partitions actives sont généralement les partitions contenant des données récentes telles que les dates de vente récentes. Les partitions froides contiennent souvent des données moreover anciennes, qui sont moins susceptibles d’être lues.
De moreover, lorsque les données vieillissent, elles sont généralement interrogées en gros morceaux, par exemple par mois ou même par année. Voici quelques exemples pour catégoriser sans ambiguïté les données du chaud au froid :
- Chaud : données de la semaine en cours.
- Moins chaud : données des semaines précédentes mais du mois en cours.
- Froid : Données des mois précédents mais de l’année en cours.
- Moreover froid : données de l’année dernière et antérieures.
Pour réduire l’ambiguïté entre les données chaudes et froides, nous devons trouver des réponses à deux questions. Premièrement, nous devons quantifier le chaud, le moins chaud, le froid, le in addition froid et peut-être même de plus en moreover froid. Deuxièmement, nous devons réfléchir à la manière dont nous pouvons réduire le nombre d’E/S dans le cas de la lecture de données froides. Nous ne voulons pas lire 365 fichiers, chacun représentant une partition de données d’une journée, juste pour obtenir le chiffre d’affaires de l’année dernière.
Partitionnement hiérarchique
Le partitionnement hiérarchique, illustré à la figure 7, apporte des réponses aux deux queries ci-dessus. Les données de chaque jour de la semaine en cours sont stockées dans sa propre partition. Les données des semaines précédentes du mois en cours sont partitionnées par semaine. Les données des mois précédents de l’année en cours sont réparties par mois. Les données encore plus anciennes sont partitionnées par année.
Ce modèle peut être assoupli en définissant une partition active à la put de la partition de day actuelle. Toutes les données arrivant après la partition active seront partitionnées par date, tandis que les données avant la partition energetic seront partitionnées par semaine, mois et année. Cela permet au système de conserver autant de petites partitions récentes que nécessaire. Même si tous les exemples de ce submit partitionnent les données par temps, le partitionnement non temporel fonctionnera de la même manière tant que vous pouvez définir des expressions pour une partition et leur hiérarchie.
 InfluxData
InfluxDataDetermine 7 : partitionnement hiérarchique.
Le partitionnement hiérarchique réduit le nombre de partitions dans le système, ce qui facilite sa gestion et réduit le nombre de partitions à lire lors de l’interrogation de blocs plus grands et additionally anciens.
Le processus de requête pour le partitionnement hiérarchique est le même que pour le partitionnement non hiérarchique, car il appliquera la même stratégie d’élagage pour lire uniquement les partitions pertinentes. Les processus d’ingestion et de compactage seront un peu moreover compliqués, car il sera furthermore difficile d’organiser les partitions dans leur hiérarchie définie.
Partitionnement agrégé
De nombreuses organisations ne souhaitent pas conserver les anciennes données, mais préfèrent plutôt conserver des agrégations telles que le nombre de commandes et les ventes totales de chaque produit chaque mois. Cela peut être pris en cost en agrégeant les données et en les partitionnant par mois. Cependant, étant donné que les partitions agrégées stockent des données agrégées, leur schéma sera différent des partitions non agrégées, ce qui entraînera un travail supplémentaire pour l’ingestion et l’interrogation. Il existe différentes façons de gérer ces données froides et agrégées, mais ce sont de grands sujets adaptés à un futur write-up.
Nga Tran est ingénieur logiciel chez InfluxDataet membre du InfluxDB IOx équipe, qui construit le moteur de stockage de séries chronologiques de nouvelle génération pour InfluxDB. Avant InfluxData, Nga travaillait pour Vertica Analytic DBMS depuis additionally d’une décennie. Elle était l’un des ingénieurs clés qui ont construit l’optimiseur de requêtes pour Vertica, et as well as tard, a dirigé l’équipe d’ingénierie de Vertica.
—
Le New Tech Forum offre un lieu pour explorer et discuter des technologies d’entreprise émergentes avec une profondeur et une ampleur sans précédent. La sélection est subjective, basée sur notre sélection des technologies que nous pensons importantes et les plus intéressantes pour les lecteurs d’InfoWorld. InfoWorld n’accepte pas les supports promoting pour publication et se réserve le droit de modifier tout le contenu contribué. Envoyez toutes les demandes à [email protected].
Copyright © 2022 IDG Communications, Inc.





